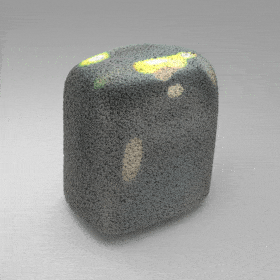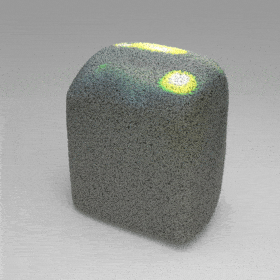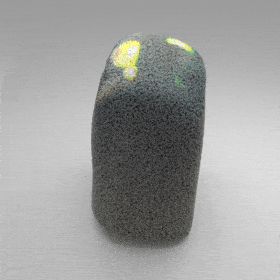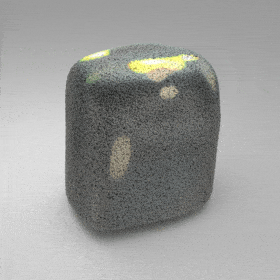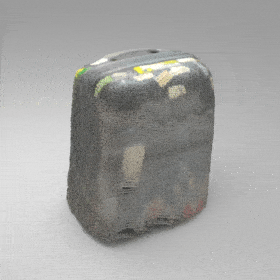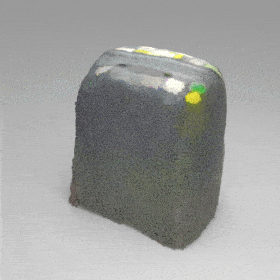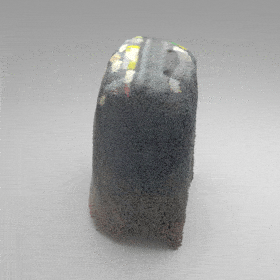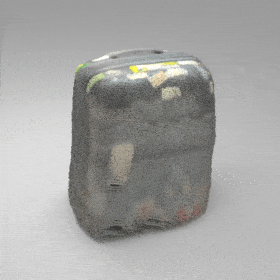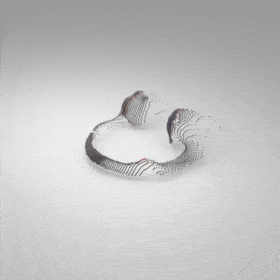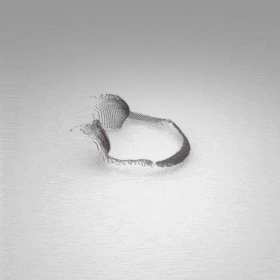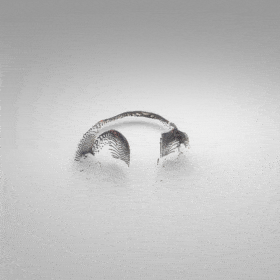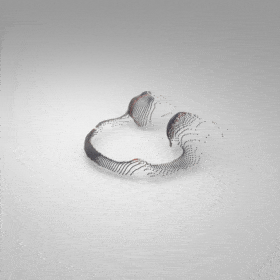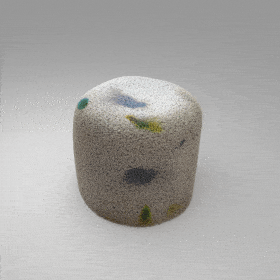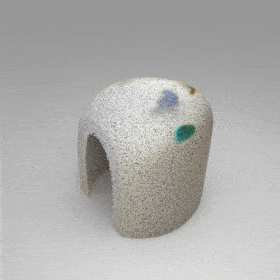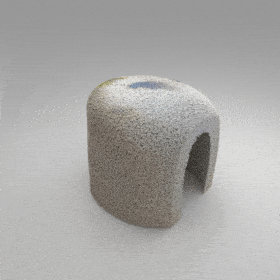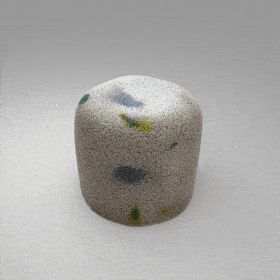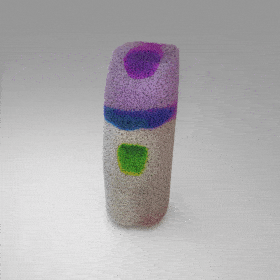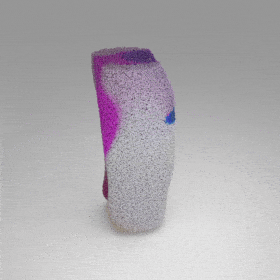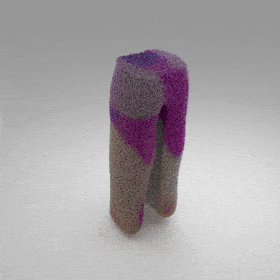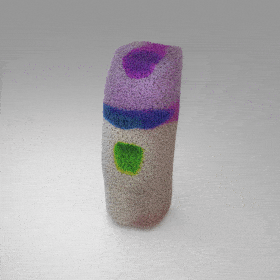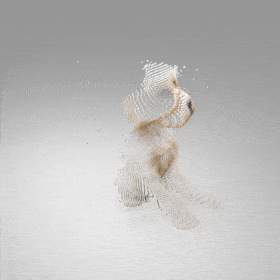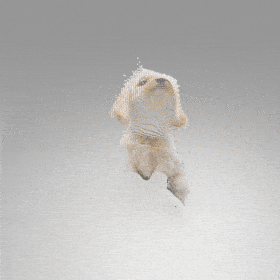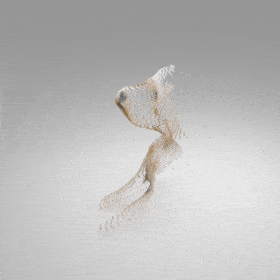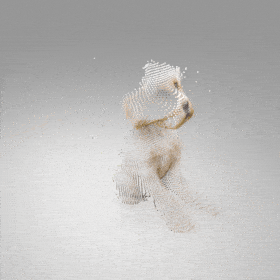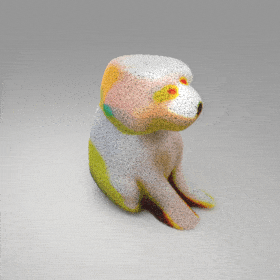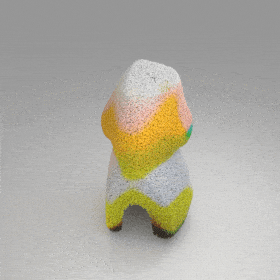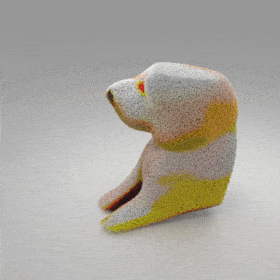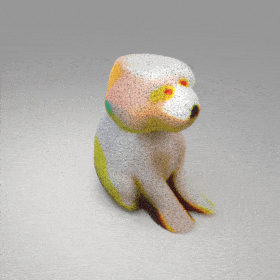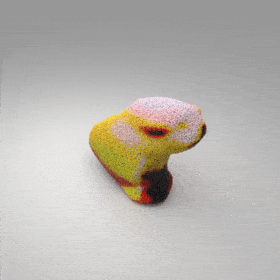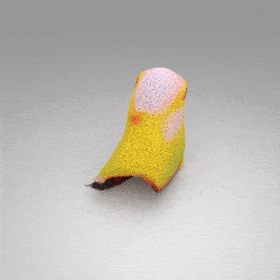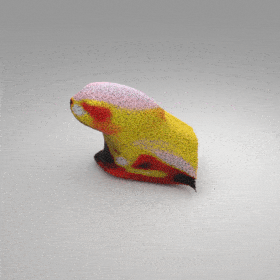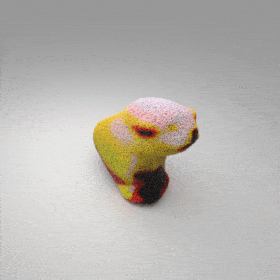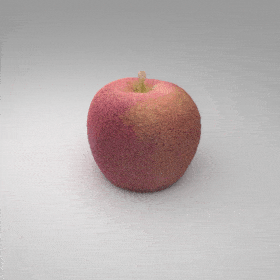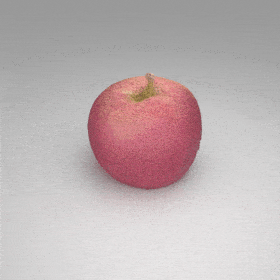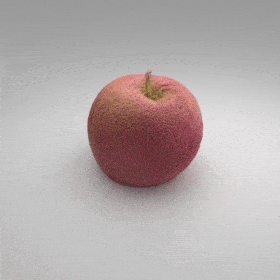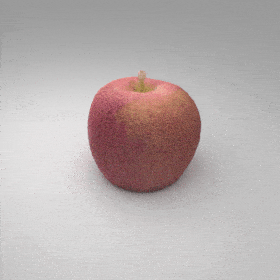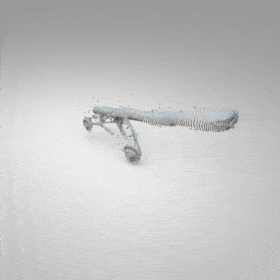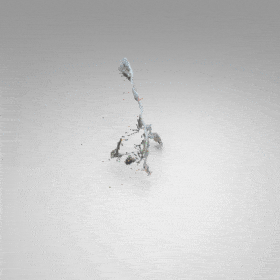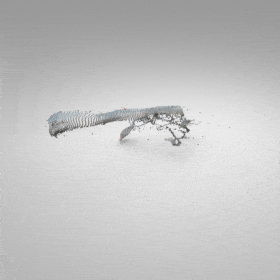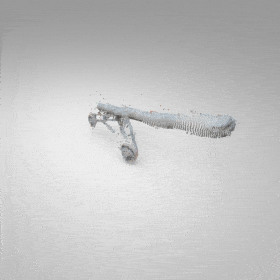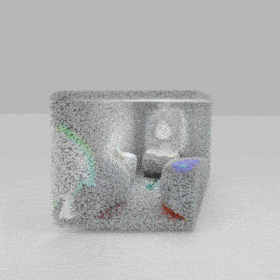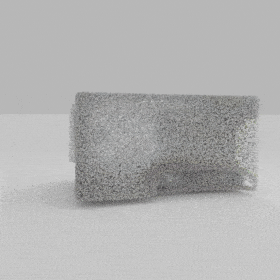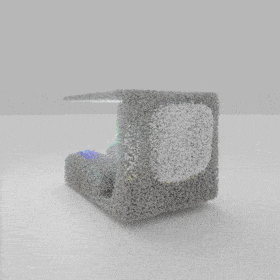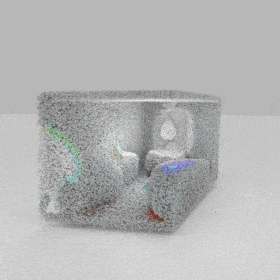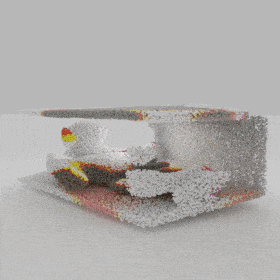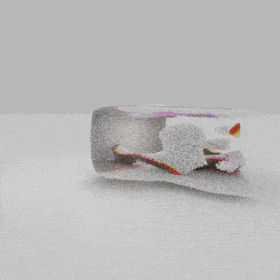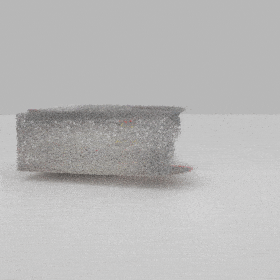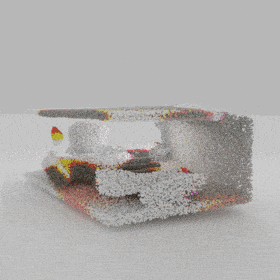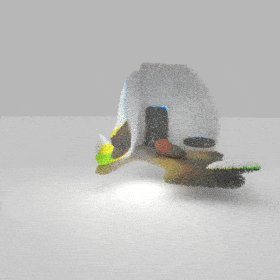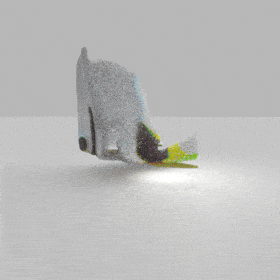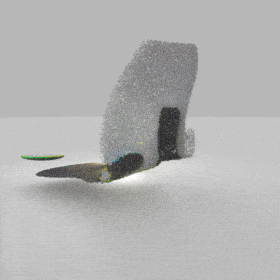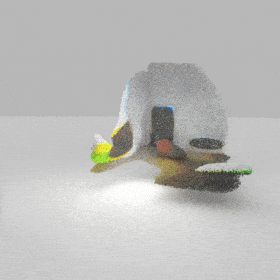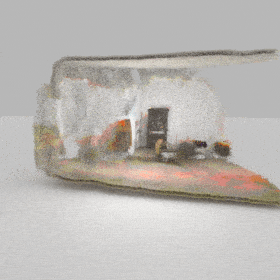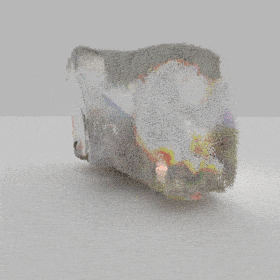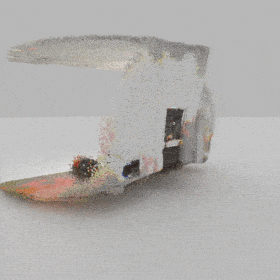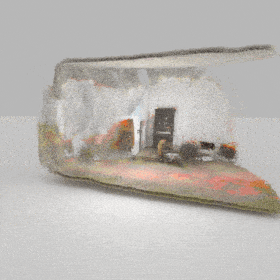Approach
Overview
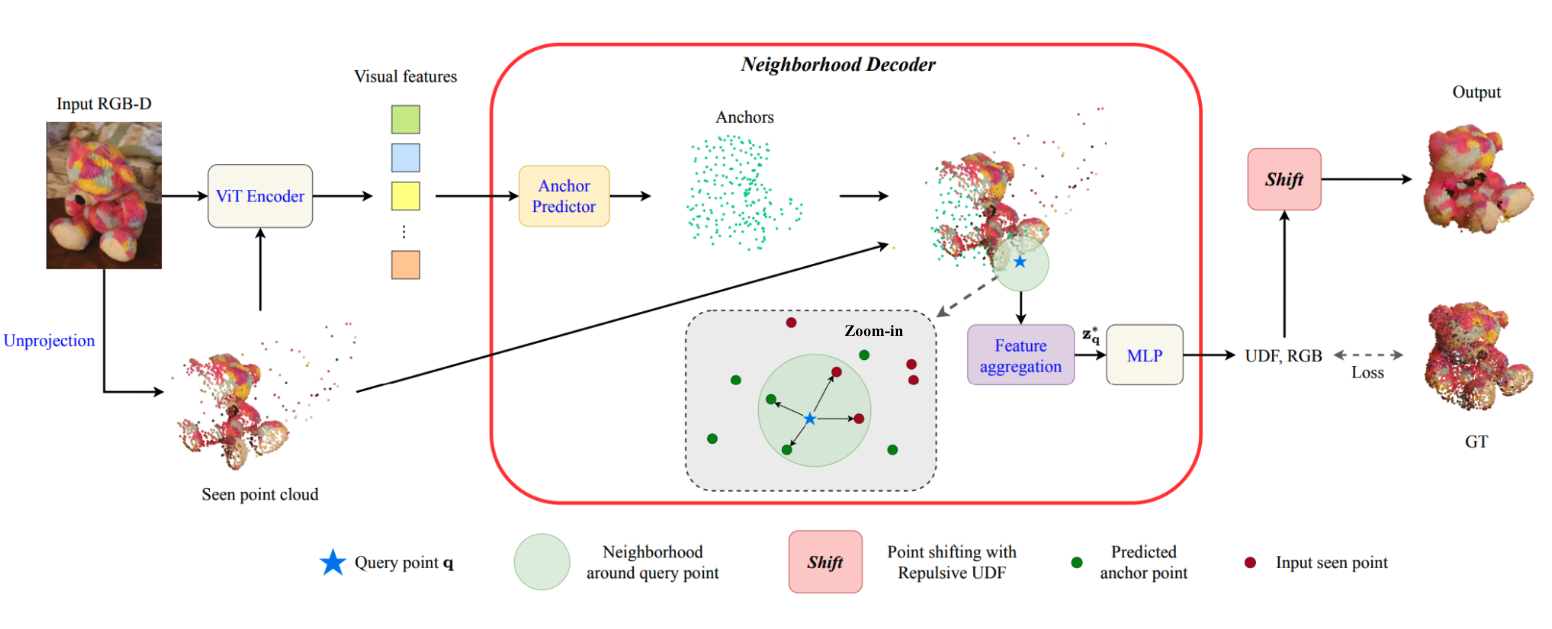 Given an input single-view RGB-D image, we first unproject the pixels into the 3D world frame, resulting in a textured partial point cloud.
We then employ a standard ViT to extract visual features from the partial point cloud. Next, we introduce our Neighborhood decoder,
which utilizes the extracted visual features to estimate the UDF and RGB values of each query point in 3D space.
The Neighborhood decoder allows each query point (blue star in the figure) to attend to only a small set of features in its neighborhood and incorporate fine-scale information
directly from the input, significantly improving the efficiency and reconstruction quality. During inference, the predicted UDF is used to shift the query points to the surface of the 3D object,
leading to high-quality 3D reconstruction. Repulsive forces between query points are employed to fix the hole artifacts in the standard UDF.
Given an input single-view RGB-D image, we first unproject the pixels into the 3D world frame, resulting in a textured partial point cloud.
We then employ a standard ViT to extract visual features from the partial point cloud. Next, we introduce our Neighborhood decoder,
which utilizes the extracted visual features to estimate the UDF and RGB values of each query point in 3D space.
The Neighborhood decoder allows each query point (blue star in the figure) to attend to only a small set of features in its neighborhood and incorporate fine-scale information
directly from the input, significantly improving the efficiency and reconstruction quality. During inference, the predicted UDF is used to shift the query points to the surface of the 3D object,
leading to high-quality 3D reconstruction. Repulsive forces between query points are employed to fix the hole artifacts in the standard UDF.
Repulsive UDF
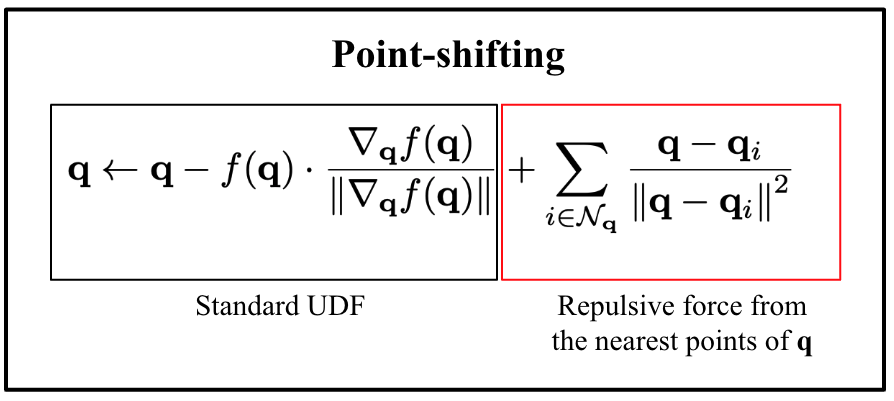
The standard UDF formulation allows the generation of dense points around surfaces by iteratively shifting query points guided by their UDFs and UDF gradients. However, the standard formulation favors regions with high-curvature and thus results in hole artifacts. We introduce repulsion forces among the query points to produce uniform point distribution on the surface.